
Counting Quotient Filter take over?
Authors: Moustafa Shokrof(1) and Tamer A Mansour(2)
- Center of Information Science, Nile University
- Department of Population Health and Reproduction, University of California, Davis, California, USA.
Approximate membership query (AMQ) data structures provide approximate representation for data using smaller amount of memory compared to the real data size. As the name suggests, AMQ answers if a particular element exists or not in a given dataset but with possible false positive errors. Counting variants of AMQs return how many times the element was seen in the set with the same one side error that may overestimate the count of the query.
Quotient filter (QF) is an AMQ that was first coined by Michael A. Bender et al as an alternative to the commonly used Bloom filter to solve its chronic poor data locality. Prashant Pandey et al published two enhanced versions of QF under the name of Rank Select Quotient filter(RSQF) and Counting Quotient Filter (CQF). khmer is a k-mer counting software that uses another AMQ called count-min sketch; a counting variant of Bloom filter. Recently Khmer has implemented a wrapper for the cqf library to test its performance. In this blog post I am using the Khmer wrapper to assess the CQF and compare it with Bloom filter and Count min sketch.
Quotient Filter

Figure 1: Quotient Filter
The above figure describes the insertion algorithm in the QF. First, the filter splits the hash-bits into two components: quotient and remaining parts. Quotient Part is used to determine the target slot. The remaining is inserted into the target slot. The insertion algorithm uses a variant of linear probing to resolve collisions. If we are trying to insert an item in an occupied slot, linear probing uses the next vacant slot. Linear probing is very simple, and has a good data locality, but it works well only when the load factor is low (reference). In Space tight conditions, long contagious occupied slots (runs) decreases the performance of both inserting and query items. QF overcomes linear probing shortcoming by two changes. First, it keeps items in the run in a sorted order. Second, it uses 3 bits of metadata to determine the start and the end of the runs.
RSQF and CQF
Prashant Pandey et al introduced significant improvements to the QF idea. They developed two new filters: Rank and Select Quotient Filter (RSQF) and Counting Quotient Filter (CQF). RSQF differs from QF into two major points. First, RSQF uses different metadata scheme than QF. Instead of 3 bits per slot, RSQF uses only 2.125 bits per slot. RSQF also deploys rank and select methods to speed up the search process. Unlike classical QF that slows down when the load factor exceed 70%, RSQF works efficiently up to high loading capacity (~95%). Second, RSQF splits the filter into blocks to store the metadata close to their slots. Therefore, RSQF has better data locality than QF.
CQF uses the same insertion strategy as RSQF, however it allows counting the number of instances inserted. If the item inserted more than once, enough slots immediately following that element’s remainder are used to encode for its count.
Quotient Family Advantages
- QF has better data locality than bloom filter. Items are saved in one place. Therefore, QF is efficient when stored in main memory since it produces fewer cache misses than bloom filter. Also QF performs better when stored on SSD disk because it decreases I/O traffic.
- QF can be merged easily, like merging sorted lists. Bloom filters can be merged easily as well by using OR operation but only if they have the same size. In case of QF, we should be able to merge filters of different sizes.
- QF resizing is possible in streaming fashion.
- RSQF uses less metadata than QF, and it performs well when the filter is filled up to 95% of its capacity.
- CQF uses variable size counters. So, it is more memory efficient for counting data following (zipifan distribution) where most the items occur once or twice but few items can happen in very high counts.
CQF Assessment
All the tests below can be found on my khmer github repository. Testing was done on t2.medium instance of AWS using linux v16.04.
Install required software
sudo apt-get update && sudo apt-get install python3-dev python3-venv python3-pip gcc g++ git astyle gcovr cppcheck enchant parallel python3-tk libssl-dev
git clone -b testCQF --single-branch https://github.com/dib-lab/khmer.git && cd khmer
python3 -m venv ../khmerEnv && source ../khmerEnv/bin/activate
make install-dep
make
pip3 install numpy matplotlib
cd testsCQF
## You can generate the test data and run all the tests by running:
bash runTests.sh
Dataset Description
Simulated datasets of 20 bp k-mers were designed for testing CQF and comparing it with bloom filter and count-min sketch. Simulated datasets include:
- Unique dataset: 1M unique k-mers only.
- Zipifan dataset: 47M total k-mers sampled from the unique dataset following zipifan distribution (Figure 2)
- TruekmerCount: k-mers count in format “kmer\tcount”
- Unseen dataset: 10K k-mers that don’t exist in the previous dataset.
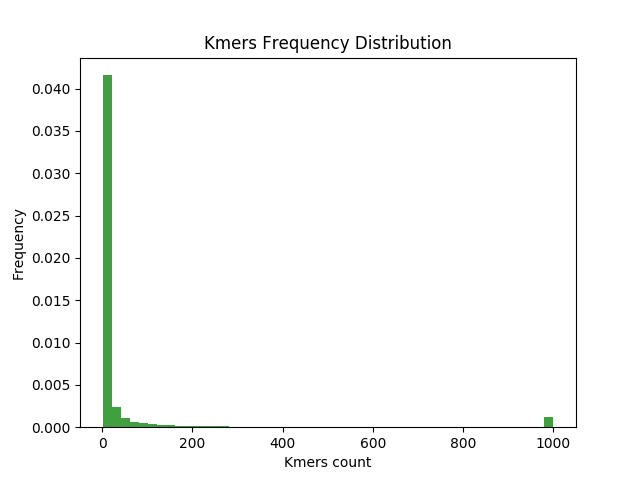 Figure 2: the frequency distribution of the Zipifan dataset
Figure 2: the frequency distribution of the Zipifan dataset
Tests:
- CQF Construction Test
- CQF unit-test
- Load factor Test
- Accuracy Test
- Merging & possible resizing test
- Size Doubling
CQF Construction Test
CQF construction takes two values: the number of slots(2^q), and the number of hash bits(q+r). CQF usage example is used as template for testing. r(key remainder size) is calculated by subtracting q from the number of hash bits. CQF succeeds to construct filters using different values of q. However changing r value from 8 to any other value violates assertion that r must be equal to hard coded variable(BITS_PER_SLOT=8).
If BITS_PER_SLOT is set to 0 in gqf.h, The code passes the assertion and successfully constructs the filter. The new CQF passes Tests in main.c. However, I am not sure the change in the code affects other functions in cqf library; I asked the autohrs on github, and they replied
CQF Unit Test
I borrowed some test cases from Khmer to test CQF. The test cases cover simple inserting/querying items into the filter, saving filter to hard disk, and loading from hard disk. All the test cases passed except inserting highly frequent items (>65535). CQF dynamically allocate bigger counters for high frequent items. However, the largest counter is 2 bytes; therefore, It can count up to 65535. If we try to count more than 65535, the counter overflows and restarts counting. According to the definition of the variable counter in CQF, it should be able to expand but at least it should maintain the maximum value and report to the user.
Load Factor Test
To find the maximum loading factor that can be achieved by CQF, a filter with known capacity was created then k-mers from the unique dataset were inserted M times (Values of M are 2^i-1 for i in 1:16) until the filter fails. During insertions and to ensure accurate calculation of the load factor, k-mers that might have collisions with the pre-inserted items were avoided. The load factor can be calculated by dividing the number of k-mers inserted by the capacity of the filter. Our test CQF was created by passing 2^13 slots as an input. This filter should have 8192 slots but actually the current software created 9152 slots. Exploring the code showed that the constructor of the filter add 10*sqrt(Number of Slots). Authors explain that the extra slots are added to handle the overflow in the last block. The maximum numbers of unique k-mers that can be inserted were recorded (figure 3 and figure 4).
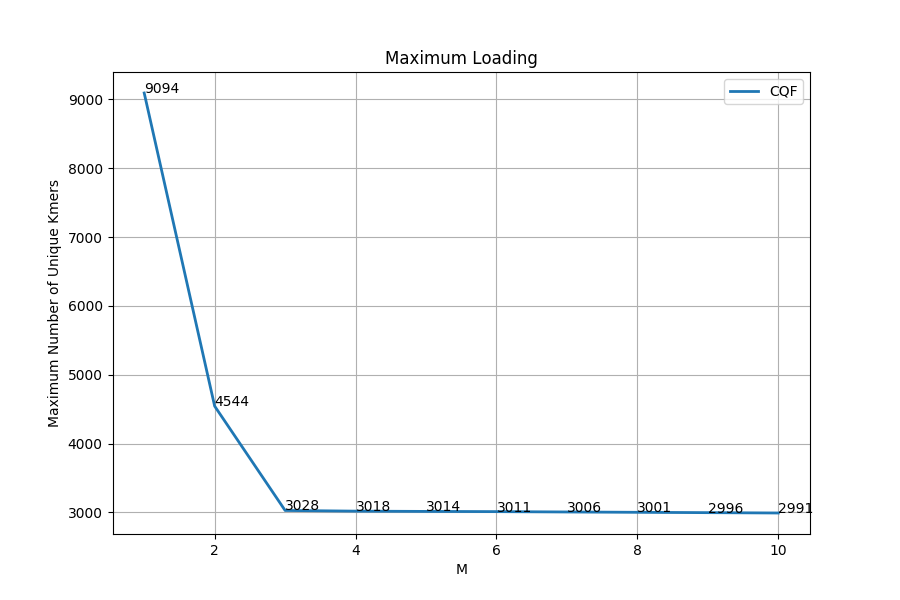 Figure 3: Maximum Loading of CQF using uniform distribution.
Figure 3: Maximum Loading of CQF using uniform distribution.
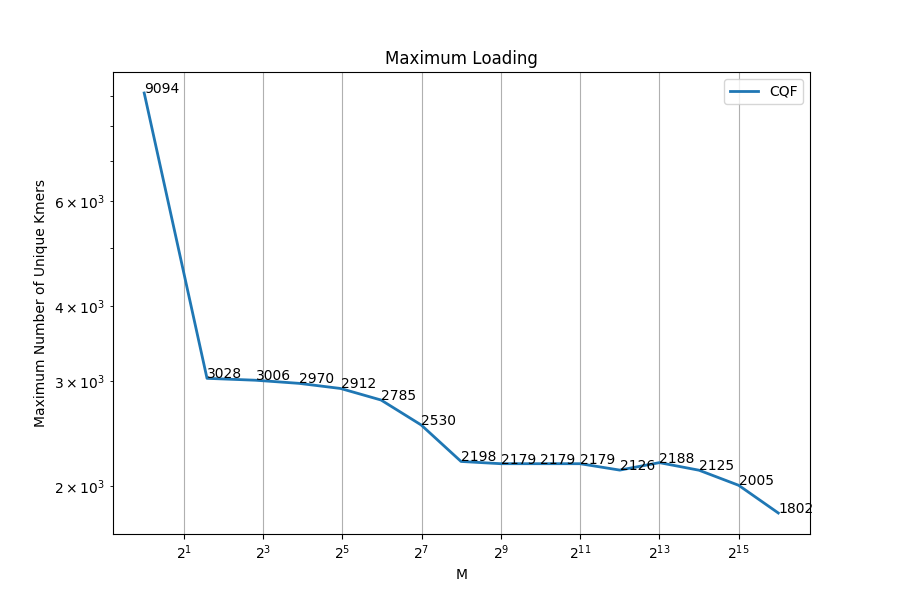 Figure 4: Maximum Loading of CQF using uniform distribution(x-axis uses log scale).
CQF successfully inserted 9097 unique k-mers(M=1) into the 9152 slots which leads to 99% load factor. With 1 fold increase in k-mers repetition (M=2), The maximum number of unique k-mers that can be inserted decreased to 49%. Another sharp reduction to 33% happened with another fold increase in k-mers repetition (M=3). The decrease is due to CQF using slots to encode for counters. The reduction of the maximum allowed unique k-mers continued gradually until the highest tested repetition (log2(M)=16). Two reasons might explain this continuous reduction:
Figure 4: Maximum Loading of CQF using uniform distribution(x-axis uses log scale).
CQF successfully inserted 9097 unique k-mers(M=1) into the 9152 slots which leads to 99% load factor. With 1 fold increase in k-mers repetition (M=2), The maximum number of unique k-mers that can be inserted decreased to 49%. Another sharp reduction to 33% happened with another fold increase in k-mers repetition (M=3). The decrease is due to CQF using slots to encode for counters. The reduction of the maximum allowed unique k-mers continued gradually until the highest tested repetition (log2(M)=16). Two reasons might explain this continuous reduction:
- CQF increases the counters’ size to use extra slots to handle the big counts which could explain the big reduction seen at log2(M)=8
- With gradual increase of M value, it is more likely to be bigger than the remaining value (r) encoding for the k-mer. CQF has a special encoding scheme that add extra slot to tag these counters.
Accuracy Test
I am trying to compare the accuracy of CQF, Bloom filter and count-min sketch wrapped in Khmer.
Experiment 1 Quotient Filter Vs Bloom filter
Experiment 1 compares CQF and Bloom filter. Both filters are created with size approximate to 524k. Then, Unique k-mers are iteratively inserted in both filters. Accuracy is measured periodically every 20,000 k-mers. Accuracy measure is the number of false positives found while querying unseen k-mers dataset.
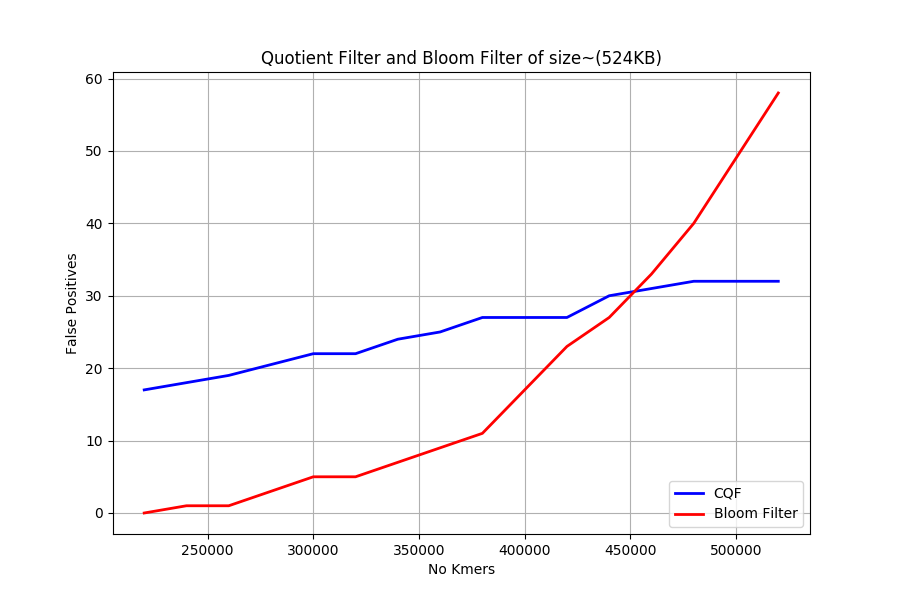 Figure 5: Accuracy Comparison: Bloom filter Vs CQF
CQF’s false positive grows slowly and steadily until the filter is completely filled. FPR values don’t differ too much between empty and full filters. On the other hand, Bloom filter has lower FPR when the filter is near empty and half filled. After Saturation, FPR grows exponentially. K-mers can be further inserted into saturated bloom filter at the expense of higher FPRs.
Figure 5: Accuracy Comparison: Bloom filter Vs CQF
CQF’s false positive grows slowly and steadily until the filter is completely filled. FPR values don’t differ too much between empty and full filters. On the other hand, Bloom filter has lower FPR when the filter is near empty and half filled. After Saturation, FPR grows exponentially. K-mers can be further inserted into saturated bloom filter at the expense of higher FPRs.
Experiment 2 (CQF Vs Count-min sketch):
Experiment 2 compares the accuracy of CQF and count-min sketch. Six instances of each structure were created to cover a range of different sizes (8M-268M). Same numbers of k-mers from the Zipifan dataset were inserted into all data structures. Box plots are drawn for the differences between the true and observed counts of k-mer queries using k-mers from Zipifan (Figure 6) and unseen datasets (Figure 7).
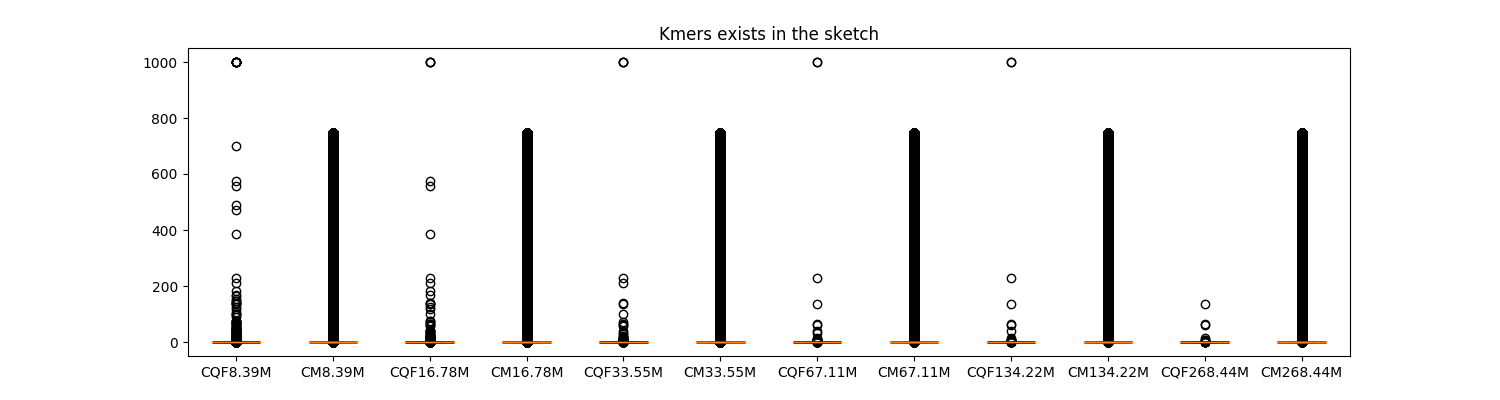 Figure 6: Accuracy Comparison using the Zipifan dataset.
Figure 6: Accuracy Comparison using the Zipifan dataset.
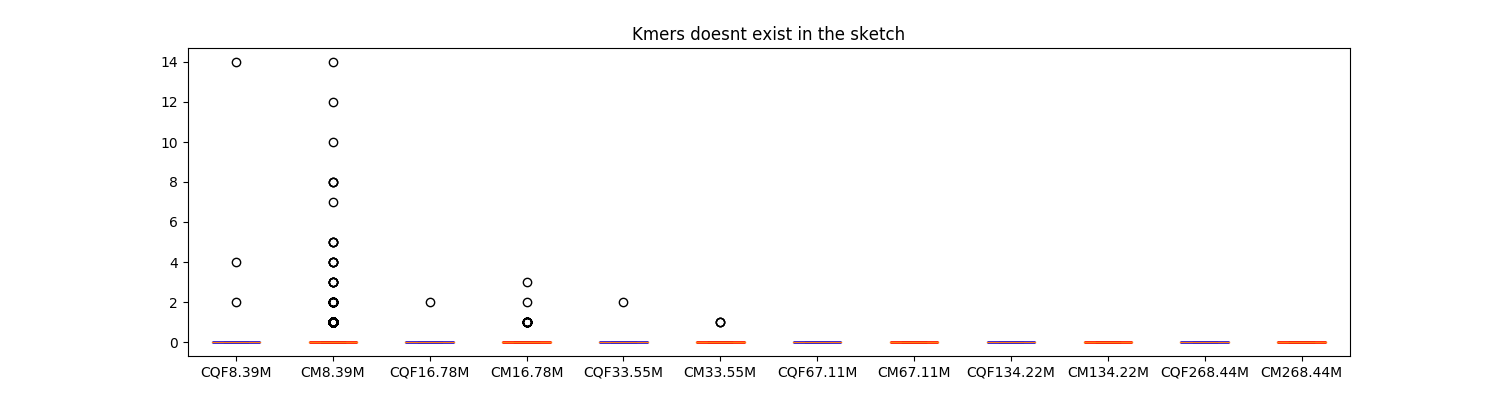 Figure 7: Accuracy Comparison using the unseen dataset.
The CQF has fewer but more scattered error compared to the count-min sketch.
Figure 7: Accuracy Comparison using the unseen dataset.
The CQF has fewer but more scattered error compared to the count-min sketch.
Merging and possible resizing test
Quotient filters can be merged if they have been constructed using the same total number of hash bits. With the current implementation of CQF, merging two CQF into a new one was successful as long as all of them have the same size.
Different QFs might use the same total number of hash bits but have different sizes because of using different quotient and remaining parts. These filters can be - theoretically - merged. Also resizing - which is not implemented in the current CQF library- can be done by merging the full small CQF into a larger empty one with the same no of hash bits but using smaller r value. As expected, testing of both ideas fail using the current implementation of CQF merge function because of the inability of the package to construct filters with different remaining parts, see CQF Construction Test.
Merging and resizing can be tested when BITS_PER_SLOT in gqf.h is set to 0. Both tests(Merging Filters of Different sizes Test,Resizing Test) are passed.
Size Doubling
CQF uses power-of-2 sizes. It is very efficient method since bit shifting can be used to calculate modulus operation. Also, Dividing the hash values into quotient and remaining can be done using bit masks. However, it has two disadvantages.
- Growing the CQF using size doubling technique is impractical for huge filter. For example, if you want to grow a 32GB sketch, you will need 64GB of RAM which may not available.
- It does not allow using prime sizes which is a usual best practice to avoids data clustering with unevenly distributed hash codes. ref
Choosing number of slots(q) and remaining part size(r)
CQF and RSQF false positive rate(\(\delta\)) depends on \(r\) and the load factor(\(\alpha\)), which depends on \(q\). However, the upper pound of \(\delta\) depends only on \(r\) which equals to \(2^{-r}\). Therefore, r can be calculated using the formula \(r=-log_2(\delta)\). The formula is similar to to the one use to calculate the optimal number of hash functions(\(k\)) for bloom filter, \(k=-log_2(\delta)\).
\(q\) can be calculated from the number of elements to be inserted in the filter and \(\delta\). In RSQF, every item is inserted in one slot, and the filter can’t be 100% filled. Therefore, number of slots equals to \({N}/{\alpha}\). Since RSQF can withstand high load factor, we can substitute \(\alpha\) with 0.95.
\[q=\lceil log_2(1.05N)\rceil\]CQF uses slots for storing items and counters(how many the item is repeated(\(C\))). CQF uses in worst case 1 slot to store singletons, 2 slots to store doubleton, and \(4+2log_2(C)\) slots to store elements repeated more than 2 times. Suppose a Dataset of \(X\) unique item following a distribution where \(P(C=i)\) is the probability of an element to be repeated \(i\) times. Number of slots to be used(U) can be calculated using the following formula.
\[U = X*P(C=1) + 2X*P(C=2) + \sum_{i\geq3} (X*P(C=i)*( 4+2log_2(i) ))\] \[q = \lceil log_2(1.05U)\rceil\]CQF adds extra slots to the filter to avoid overflow. Therefore, the number of bits required for the filter equals to \((q+10*\sqrt{q})*(r+2.125)\).
Assessment Remarks
- CQF has lower false positive rate than bloom filter when filters are highly loaded, see Accuracy Test.
- When the QF is fully loaded, the code just fail.
- Sketch uses variable length counter for each k-mer until the count exceeds 65535. The counter overflow and the value resets (CQF Unit Test)
- Sketch size can only be of the power-of-two. If you want to increase the sketch size you need to double it (See Size Doubling).
- CQF need to have the same size to be merged(See Merging Issue).
- Resizing is not implemented in the CQF library, and It can’t be implemented using the current CQF library.(See resizing issue)
- CQF produces larger counting errors, but less often than the count-min sketch (See accuracy test).